
Amazon S3 (Amazon Simple Storage Service)
Day 7-Part 1: Prep- AWS Certified Cloud Practitioner | CLF-C02

Experienced Technical developer with 6+ years' global collaboration.
Proficient in Python, Go, React, Next.js, Django, various databases, Cloud & DevOps (AWS EC2, Docker, Kubernetes), and Big Data tools.
Skilled in data structures and algorithm, API development, and end-to-end software engineering.
Excels in back-end development, front-end design, Root Cause Analysis, and product management to deliver superior user experiences.
Holds a master’s degree in computer engineering.
Link to exam: https://aws.amazon.com/certification/certified-cloud-practitioner/
Introduction
Amazon S3, or Simple Storage Service, is like a giant virtual storage room provided by Amazon Web Services (AWS). It lets you securely store and access all kinds of data online. You can create storage areas called "buckets" and put your files in them. These files are kept safe on multiple servers around the world, so you can access them from anywhere with an internet connection. S3 makes it easy to manage your data, making it a must-have tool for individuals and businesses in the digital age.
In this comprehensive guide, we'll delve into the world of Amazon S3, breaking down its features, benefits, use cases, and how it works in simple language.
What is Amazon S3?
Amazon S3, short for Simple Storage Service, is a scalable, secure, and highly available cloud storage service provided by Amazon Web Services (AWS). It enables individuals and businesses to store and retrieve any amount of data at any time from anywhere on the web. Whether you're storing text files, images, videos, or databases, Amazon S3 offers a reliable solution for data storage needs.
How Does Amazon S3 Work?
At its core, Amazon S3 operates on a simple premise: objects and buckets.
When you upload an object to Amazon S3, you specify the target bucket and a unique key (i.e., the object's name within the bucket). Amazon S3 then stores the object redundantly across multiple servers and data centers to ensure durability and availability.
Let's break them down
1. Objects
In Amazon S3, data is stored as objects, which can be files, images, videos, or any other type of data. Each object comprises:
Object Value: Object Value refers to the content stored within the object, spanning from a few bytes to a colossal 5TB in size. For objects exceeding 5GB, Amazon S3 employs a "multi-part upload" approach, enabling data storage in 5GB segments, with the capability to accommodate up to 1000 segments in total.
Metadata: Objects can have metadata, which is a list of text key/value pairs. This metadata can be system-generated or defined by the user, including information such as content type and creation date.
Tags: Tags are Unicode key/value pairs (up to 10) that can be attached to objects, useful for purposes like security and lifecycle management.
Version ID: If versioning is enabled for the bucket, each object will have a unique version identifier.
Each object is uniquely identified and stored within a flat namespace within a bucket. Objects are referenced using a key, which represents the full path to the object. Despite the appearance of directory-like structures in the UI, S3 does not have actual directories; instead, it employs keys with slashes ("/") in their names.
Example:
So, when you upload "my_image.jpg" to the "my-bucket" bucket and specify the key as "images/my_image.jpg," it's like saying you're putting the image inside a folder named "images" within the bucket.
Here, "images/" acts as a prefix, and "my_image.jpg" is the object name.
Here's how it looks:
makefileCopy codeBucket: my-bucket
├── images/
│ └── my_image.jpg
In reality, there's no physical folder called "images" within the bucket. It's just part of the object's key. This key uniquely identifies the object and helps you organize and retrieve your data efficiently within Amazon S3.
2. Buckets:
Buckets are containers for storing objects. They provide a logical way to organize and manage data within S3. Key aspects of buckets include:
Unique Names: Each bucket must have a globally unique name across all regions and all accounts.
Region-Level Definition: Buckets are defined at the region level. Although S3 appears as a global service, buckets are created within specific regions.
Example:
If you have two AWS accounts, both cannot create a bucket with the same name in the same region.
For instance, if "my-bucket" exists in the US East (N. Virginia) region, another user cannot create a bucket with the same name in the same region.
However, while "my-bucket" may exist in the US East (N. Virginia) region, it can still be used as a bucket name in other regions, such as US West (Oregon), EU (Ireland), or any other region.
Each region maintains its own namespace for bucket names, allowing for the same bucket name to be used in different regions without conflict.
Difference Between Public URLs and Pre-signed URLs for Amazon S3 Objects
When you upload a file to an Amazon S3 bucket, you can access it via a public URL or a pre-signed URL.
Public URL:
This URL provides direct access to the file on the internet.
However, by default, objects in S3 buckets are private, so attempting to access them via a public URL will result in an "Access Denied" error.
Public URLs do not include any credentials or signatures. They are straightforward URLs that anyone can use.
Making an object public allows anyone with the URL to access it.
Pre-signed URL:
A pre-signed URL is a secure way to grant temporary access to a specific S3 object.
It includes a signature that verifies the requester's identity, allowing access only to authorized users.
These URLs are typically long and complex, containing encoded credentials.
Pre-signed URLs are generated programmatically by the bucket owner and typically have an expiration time.
They grant temporary access to the object for the specified duration, after which the URL becomes invalid.
Pre-signed URLs are useful for sharing private content securely, such as providing access to specific files for a limited time without making them public.
In summary, public URLs provide straightforward access to objects but require the objects to be public, while pre-signed URLs offer temporary and secure access to private objects without exposing them to the public.
Key Features of Amazon S3
Scalability: Amazon S3 can scale seamlessly to accommodate any amount of data, from gigabytes to exabytes, without any upfront provisioning.
Durability and Availability: Amazon S3 is designed for 99.999999999% (11 nines) durability, meaning your data is highly resilient to hardware failures and data loss. It also offers high availability, ensuring your data is accessible whenever you need it.
Security: Amazon S3 provides several layers of security, including encryption at rest and in transit, access control lists (ACLs), and bucket policies. You can also integrate with AWS Identity and Access Management (IAM) for fine-grained access control.
Lifecycle Policies: You can define lifecycle policies to automate the transition of objects between different storage classes (e.g., from Standard to Infrequent Access) or to expire objects after a certain period, helping optimize storage costs.
Versioning: Amazon S3 supports versioning, allowing you to preserve, retrieve, and restore every version of every object stored in your bucket. This feature is invaluable for data protection and compliance.
Cross-Region Replication: You can replicate objects between different AWS regions to enhance data redundancy and disaster recovery capabilities.
Amazon S3 – Durability and Availability:
Durability:
Durability Rating: Amazon S3 provides eleven 9's (99.999999999%) durability for stored objects.
Example: Storing 10,000,000 objects, expect to incur a loss of a single object once every 10,000 years on average.
Achieved Through: Redundant storage and data replication across multiple devices and facilities within an AWS Region.
Automatic Detection and Repair: S3 automatically detects and repairs any data corruption or loss.
Availability:
Definition: Measures how readily available a service is.
High Availability: S3 offers high availability, with service level agreements (SLAs) guaranteeing uptime of 99.99% or higher, which means it's not available for approximately 53 minutes a year.
Variation byStorage Class: Availability varies depending on the storage class.
Access: Data stored in S3 is accessible from anywhere with an internet connection.
Infrastructure Resilience: S3 employs distributed systems architecture, storing data across multiple Availability Zones (AZs) within a region.
Redundancy and Fault Tolerance: S3's built-in redundancy and fault-tolerant design minimize the risk of service disruptions, ensuring continuous availability of data.
Getting Started Hands-On with Amazon S3: A Step-by-Step Guide
For a thorough walkthrough of Amazon S3 console operations, from creating buckets to managing objects, organizing files, and understanding object URLs, delve into our comprehensive guide. Visit AWS S3 Console Hands-On | A Step-by-Step Guide for detailed instructions and insights.

Amazon S3 – Security Features and Encryption:
Amazon S3 (Simple Storage Service) ensures robust data security with encryption at rest and in transit, access control lists (ACLs), bucket policies, and seamless integration with AWS IAM.
Encryption options include Server-Side Encryption (SSE) and Client-Side Encryption. ACLs and bucket policies enable precise access control, while IAM integration allows granular permissions management.
For a comprehensive exploration of Amazon S3's security features and how they can fortify your data protection strategy, delve into our detailed guide at the following link: Full Guide: AWS S3 – Security Features
Amazon S3 – Static Website Hosting:
Overview:
Convenient and cost-effective solution for hosting static websites.
Serve HTML, CSS, JavaScript, and other web assets directly from S3 buckets.
Creates highly available and scalable websites.
Configuration:
Configure bucket settings for static website hosting.
Specify index document (e.g., "index.html") and error document.
Bucket Policy:
Ensure the bucket policy permits public reads to prevent 403 Forbidden errors for website visitors.
This step ensures that the website content is accessible to anyone accessing the website URL.
Website URL Format:
Format depends on the region:
Static Website Hosting: Hands-On | A Step-by-Step Guide
Dive into our comprehensive guide on enabling static website hosting in Amazon S3. Follow along step-by-step for detailed instructions and insights. For the full guide, visit Amazon S3 Static Website Hosting: Hands-On | A Step-by-Step Guide.

Amazon S3 - Versioning:
Overview:
- Versioning preserves, retrieves, and restores every version of objects stored in the bucket.
Functionality:
Enables tracking changes over time with unique version IDs for each object version.
Creates new versions with incremented version numbers upon same-key overwrite.
Benefits:
Protects against accidental deletion or overwrite by maintaining multiple versions.
Facilitates easy rollback to previous versions if needed.
Management:
Versioning can be enabled or suspended at any time at the bucket level.
Objects without versioning prior to enabling will have a version set to "null."
Data Integrity:
Suspending versioning does not delete previous versions, ensuring data integrity.
Complies with retention policies by retaining all versions.
Permanent Deletion:
Objects, including all versions, can be permanently deleted from an S3 bucket even with versioning enabled.
Deletion is done using the DELETE operation.
When deleting an object from a versioned bucket without specifying a version ID, S3 adds a delete marker.
The delete marker hides the current version, making the previous version the current one.
To permanently delete all versions, including the delete marker, specify the version ID in the DELETE operation.
Once deleted, objects and their versions cannot be recovered.
Important Considerations: Exercise caution when permanently deleting objects, especially in production environments, to prevent data loss.
Amazon S3 Versioning: Hands-On | A Step-by-Step Guide
Ready to enhance your data management with versioning in Amazon S3? Explore our comprehensive guide for a detailed walkthrough on enabling and utilizing versioning features. Follow along step-by-step to leverage the full potential of Amazon S3 versioning. For the complete guide, visit Amazon S3 Versioning: Hands-On | A Step-by-Step Guide.
Amazon S3 – Replication (CRR & SRR):
Overview:
Enhances data redundancy, disaster recovery, and compliance through replication.
Types of Replication:
Cross-Region Replication (CRR):
Asynchronously replicates objects between different AWS regions.
Ensures data resilience against region-wide outages and compliance requirements for data residency.
Lower Latency Access
Same-Region Replication (SRR):
Replicates objects within the same region.
Provides additional copies of data for fault tolerance, compliance, log aggregation
Live replication between environments like production and test accounts.
Batch Operations in S3 Replication
Efficiency: Manage large-scale data transfers efficiently.
Replication of Existing Objects: Enables replication of existing objects not automatically replicated.
Automation: Automate repetitive tasks like lifecycle policy management.
Cross-Region Replication: Facilitates efficient replication between buckets in different regions.
Scheduled Execution: Tasks can be scheduled to run at specific times.
Cost-Effective: Minimizes data transfer costs and optimizes storage usage.
Monitoring and Logging: Provides monitoring, logging, and troubleshooting capabilities.
Integration: Integrates with other AWS services like CloudWatch and SNS.
API and CLI Support: Can be performed via AWS Management Console, CLI, or SDKs.
Key Points:
Must enable versioning in source and destination buckets
Replication can occur between buckets in different AWS accounts.
Proper IAM permissions must be granted to S3 for replication to function seamlessly.
Copying is asynchronous, and buckets involved in replication must have appropriate settings configured.
Amazon S3 Replication: Hands-On | A Step-by-Step Guide
Interested in implementing replication for enhanced data durability and availability in Amazon S3? Delve into our detailed guide for step-by-step instructions on setting up and managing replication in Amazon S3. Follow along to leverage the benefits of replication for your storage needs. For the full guide, visit Amazon S3 Replication: Hands-On | A Step-by-Step Guide.

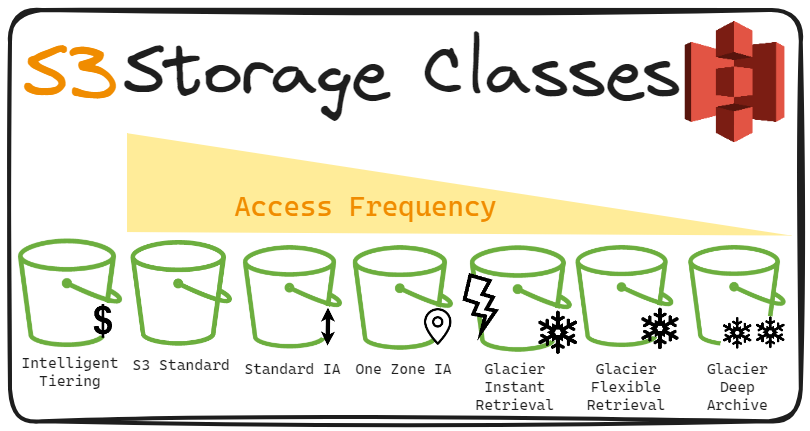
Amazon S3 – Storage Classes
Amazon S3 – Storage Classes" delves into the various storage classes offered by Amazon Simple Storage Service (S3), each tailored to specific data access patterns, durability requirements, and cost considerations. This comprehensive guide explores how these storage classes enable users to optimize their storage strategies based on the unique needs of their data workloads.
For an in-depth examination of Amazon S3 storage classes and their practical applications, refer to the full guide available at AWS S3 – Storage Classes.
IAM Access Analyzer for S3
IAM Access Analyzer for S3 offers automated security analysis to identify and rectify unintended access to S3 buckets:
Automated Security Analysis: Continuously monitors S3 bucket policies, ACLs, and access point policies to detect vulnerabilities and flag unintended access.
Risk Identification: Identifies overly permissive settings to ensure only authorized access to S3 buckets, reducing the risk of data breaches.
Policy Recommendations: Provides actionable suggestions to tighten access controls and mitigate security risks, enhancing data privacy and compliance.
Data Privacy and Compliance: Enforces data privacy by identifying and resolving potential data exposure risks, aiding in regulatory compliance.
Integration with IAM: Seamlessly integrates with AWS IAM for simplified access management and policy enforcement across S3 resources.
Continuous Monitoring: Ensures ongoing compliance and adherence to security best practices, reducing the likelihood of unauthorized access incidents.
Enhanced Security: Minimizes the risk of data breaches and unauthorized access, bolstering overall security posture.
Cost-Effectiveness: Proactively identifies and addresses vulnerabilities, helping to minimize security risks and associated costs.
Use Cases: Ideal for securing sensitive data stored in S3 buckets, maintaining regulatory compliance, and preventing unauthorized access incidents.
Snow Family
The AWS Snow Family comprises purpose-built devices tailored to efficiently and securely transfer large volumes of data to and from the AWS Cloud, ideal for environments with limited or unreliable network connectivity. Consisting of AWS Snowcone, AWS Snowball, and AWS Snowmobile, each device offers distinct capabilities to suit diverse use cases.
For further information, refer to the comprehensive guide on the AWS Snow Family at the following link: AWS Snow Family Guide

Hybrid Cloud for Storage with AWS
AWS advocates for hybrid cloud solutions where part of the infrastructure is on-premises, while the other part is in the cloud. This approach is suitable for various reasons such as long cloud migration timelines, security requirements, compliance needs, and IT strategy considerations.
Challenges:
S3, AWS's proprietary storage technology, poses a challenge for organizations with on-premises infrastructure.
Unlike EFS/NFS, it's not directly accessible on-premises.
Solution: AWS Storage Gateway
AWS Storage Gateway acts as a bridge between on-premise data and cloud data in S3, enabling seamless integration and hybrid storage usage.
It facilitates various use cases including disaster recovery, backup & restore, and tiered storage.
Types of Storage Gateway:
File Gateway:
Presents S3 buckets as network file shares, enabling on-premise applications to access S3 data via standard file protocols like NFS and SMB.
Volume Gateway:
Presents cloud-backed volumes as iSCSI block devices to on-premise applications. It offers two configurations:
Stored Volumes: Entire dataset is stored on-premises with asynchronous backups to S3.
Cached Volumes: Primary data is stored in S3 while frequently accessed data is cached on-premises.
Tape Gateway:
Presents a virtual tape library (VTL) interface to backup software, allowing backup data to be stored directly in S3.
AWS Storage Cloud Native Options and AWS Storage Gateway
Below table provides a concise comparison between AWS Storage Cloud Native Options and AWS Storage Gateway, highlighting their purpose, examples, characteristics, and use cases.
| Feature | AWS Storage Cloud Native Options | AWS Storage Gateway |
| Purpose | Cloud-optimized storage services | Bridge between on-premises and cloud storage |
| Examples | Amazon S3, EBS, EFS | File Gateway, Volume Gateway, Tape Gateway |
| Characteristics | Scalable, durable, integrated | Hybrid integration, data transfer, flexible use cases |
| Use Cases | Data lakes, backup, hosting | Disaster recovery, backup, tiered storage |
Benefits:
Simplifies hybrid cloud storage adoption by providing seamless integration between on-premise and cloud storage.
Enables organizations to leverage the scalability, durability, and cost-effectiveness of AWS S3 for on-premise workloads.
Use Cases for Amazon S3
Amazon S3 is versatile and can be used for a wide range of applications across various industries:
Data Backup and Archiving: Businesses can use Amazon S3 as a cost-effective and reliable solution for backing up and archiving data, ensuring data integrity and compliance with regulatory requirements.
Media Storage and Delivery: Content creators and media companies can leverage Amazon S3 to store and deliver large volumes of multimedia content, such as videos, music, and images, to users worldwide with low latency.
Big Data Analytics: Amazon S3 serves as a central data lake for storing vast amounts of structured and unstructured data, which can be seamlessly integrated with AWS analytics services like Amazon Athena, Amazon Redshift, and Amazon EMR for data analysis and insights generation.
Website Hosting: Amazon S3 can host static websites by serving HTML, CSS, JavaScript, and other web assets directly from buckets, providing a scalable and cost-efficient solution for web hosting.
IoT Data Storage: Internet of Things (IoT) devices can send data directly to Amazon S3 for storage and analysis, enabling real-time insights and actionable intelligence.
Summary Notes:
Amazon S3 Basics:
Description: Scalable cloud storage service by AWS.
Functionality: Store and retrieve data from anywhere.
Components: Objects (data files) and Buckets (containers).
Key Features:
Scalability: Accommodates data of any size.
Durability and Availability: Highly resilient and available (99.99%).
Security: Encryption, access control, and policies.
Lifecycle Management: Automates data tasks.
Versioning and Replication: Preserves versions and replicates data.
Durability and Availability:
Durability: 11 nines (99.999999999%) for stored objects, with automatic error detection and repair.
Availability: SLA guarantees 99.99% uptime, ensuring data accessibility.
Security Features:
User-Based Security: Managed through IAM, controlling user actions.
Resource-Based Security: Utilizes ACLs and bucket policies for fine-grained control.
Block Public Access: Prevents accidental exposure of data to the public internet.
Encryption Options:
Server-Side Encryption (SSE): Provides SSE-S3, SSE-KMS, and SSE-C options for data encryption.
Client-Side Encryption: Allows users to encrypt data before uploading it to S3.
Storage Classes:
Standard: Default storage class suitable for frequently accessed data.
Infrequent Access (IA): Lower-cost option for less frequently accessed data.
Glacier: Cost-effective storage for archival data with varying retrieval times.
Intelligent Tiering: Automatically optimizes storage costs based on usage patterns.
Transitioning: Allows manual or automated transitions between storage classes based on predefined rules.
IAM Access Analyzer for S3:
Purpose: Identifies and mitigates unintended access.
Functionality: Analyzes policies, offers recommendations.
Integration: Works seamlessly with IAM for access control.
AWS Snow Family
Streamlines data transfer to/from the AWS Cloud in scenarios with limited connectivity.
Components:
Snowcone: Portable device for edge environments.
Snowball Edge: Rugged data transfer device with compute capabilities.
Snowmobile: Shipping container for massive data transfers.
Data Migration:
Challenges: Connectivity, volume, security, bandwidth.
Solutions: Direct upload, offline transfer, security enhancements.
Edge Computing: Process data at or near the source with on-board computing.
AWS OpsHub: GUI tool for device management, file transfer, monitoring, and service integration.
Hybrid Cloud for Storage: AWS Storage Gateway bridges on-premise data and S3 cloud storage.
Use Cases:
Backup, Media, Analytics: Versatile solutions for various data needs.
Website Hosting, IoT: Scalable and efficient data storage options.
These concise notes provide a quick overview of Amazon S3, highlighting its features, storage classes, security measures, and practical applications across industries.




